
How Can Doctors Be Sure A Self-Taught Computer Is Making The Right Diagnosis?

Amir Kiani (from left), Chloe O'Connell and Nishit Asnani troubleshoot an algorithm to diagnose tuberculosis in computer lab at Stanford University. Richard Harris/NPR
Some computer scientists are enthralled by programs that can teach themselves how to perform tasks, such as reading X-rays.
Many of these programs are called "black box" models because the scientists themselves don't know how they make their decisions. Already these black boxes are moving from the lab toward doctors' offices.
The technology has great allure, because computers could take over routine tasks and perform them as well as doctors do, possibly better. But as scientists work to develop these black boxes, they are also mindful of the pitfalls.
Pranav Rajpurkar, a computer science graduate student at Stanford University, got hooked on this idea after he discovered how easy it was to create these models.
The National Institutes of Health one weekend in 2017 made more than 100,000 chest X-rays publicly available, each tagged with the condition that the person had been diagnosed with. Rajpurkar texted a lab mate and suggested they should build a quick and dirty algorithm that could use the data to teach itself how to diagnose the conditions linked to the X-rays.
The algorithm had no guidance about what to look for. Its job was to teach itself by searching for patterns, using a technique called deep learning.
"We ran a model overnight and the next morning I woke up and found that the algorithm was already doing really well," Rajpurkar says. "And that got me really excited about the opportunities, and the ease with which AI is able to do these tasks."
Fast forward to February of this year, and he and his colleagues have already moved far beyond that point. He leads me to a sun-filled room in the William Gates (yes, that Bill Gates) Computer Science Building.
His colleagues are looking at a prototype of a new program to diagnose tuberculosis among HIV-positive patients in South Africa. The scientists hope this program will help fill an urgent medical need. TB is common in South Africa, and doctors are in short supply.
The scientists lean into the screen, which displays a chest X-ray and the patient's basic lab results and highlights the part of the X-ray that the algorithm is focusing on.
The scientists start scrolling through examples, making guesses of their own and seeing how well the algorithm is performing.
Stanford radiologist Matthew Lungren, who is the main medical adviser for this project, joins in. He readily admits he is not great at identifying TB on an X-ray. "We just don't see any TB here" in the heart of Silicon Valley, he explains.
True to his warning, he misdiagnoses the first two cases he sees.
Rajpurkar says the algorithm itself is far from perfect, too. It gets the diagnosis right 75 percent of the time. But doctors in South Africa are correct 62 percent of the time, he says, so it's an improvement. The usual benchmark for TB diagnosis is a sputum test, which is also prone to error.
"The ultimate thought from our group is that if we can combine the best of what humans offer in their diagnostic work and the best of what these models can offer, I think you're going to have a better level of health care for everybody," Lungren says.
But he is well aware that it's easy to be fooled by a computer program, so he sees part of his job as a clinician to curb some of the engineering enthusiasm. "The Silicon Valley culture is great for innovation but it's not got a great track record for safety," he says. "And so our job as clinicians is to guard against the possibility of getting ahead of ourselves and allowing these things to be in a place where they could cause harm."
For example, a program that has taught itself using data from one group of patients may give erroneous results if used on patients from another region — or even from another hospital.
One way the Stanford team is trying to avoid pitfalls like that is by sharing their data so other people can critique the work.
Some of the most cogent analysis has come from John Zech, a medical resident at the California Pacific Medical Center in San Francisco, who is training to be a radiologist.
Zech and his medical school colleagues discovered that the Stanford algorithm to diagnose disease from X-rays sometimes "cheated." Instead of just scoring the image for medically important details, it considered other elements of the scan, including information from around the edge of the image that showed the type of machine that took the X-ray.
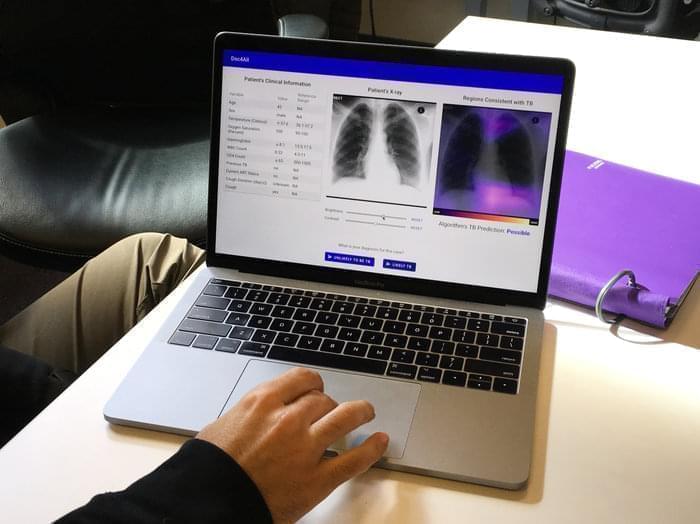
The laptop displays clinical information, a chest X-ray and a heat map that indicates where the algorithm is focusing its attention.
When the algorithm noticed that a portable X-ray machine had been used, it boosted its score toward a finding of TB.
Zech realized that portable X-ray machines used in hospital rooms were much more likely to find pneumonia compared with those used in doctors' offices. That's hardly surprising, considering that pneumonia is more common among hospitalized people than among people who are able to visit their doctor's office.
"It was being a good machine-learning model and it was aggressively using all available information baked into the image to make its recommendations," Zech says. But that shortcut wasn't actually identifying signs of lung disease, as its inventors intended.
Technologists will need to move forward carefully, to make sure they are getting rid of these biases as well as they can. "I'm interested in doing work in the field," Zech says, "but I don't think it's going to be straightforward."
Diagnosing disease is far more than an image-recognition exercise, he says. Radiologists dig into a person's medical history and talk to referring doctors at times. "Medical diagnosis is hard," he says. And he predicts it will be a long time before computers will compete with humans.
Zech was able to unearth the problems related to the Stanford algorithm because the computer model provides its human handlers with additional hints by highlighting which parts of the X-ray it is emphasizing in its analysis. That's how Zech came to notice that the algorithm was studying information along the edges of the image rather than the picture of the lung itself.
That added feature means it is not a pure black-box model, but "maybe like a very shady box," he says.
Black-box algorithms are the favored approach to this new combination of medicine and computers, but "it's not clear you really need a black box for any of it," says Cynthia Rudin, a computer scientist at Duke University.
"I've worked on many predictive modeling problems," she says, "and I've never seen a high-stakes decision where you couldn't come up with an equally accurate model with something that's transparent, something that's interpretable."
Black-box models do have some advantages: A program made with a secret sauce is harder to copy and therefore better for companies developing proprietary products.
As the Stanford graduate students' experience shows, black boxes are also much easier to develop.
But Rudin says that especially for medical decisions that could have life or death consequences, it is worth putting in the extra time and effort to have a program built from the ground up based on real clinical knowledge, so humans can see how it is reaching its conclusions.

Dr. Matthew Lungren (left) and Pranav Rajpurkar attend a lab meeting where colleagues are testing an algorithm for tuberculosis diagnosis.
She is pushing back against a trend in the field, which is to add an "explanation model" algorithm that runs alongside the black-box algorithm to provide clues about what the black box is doing. "These explanation models can be very dangerous," she says. "They can give you a false sense of security for a model that is not that great."
Bad black-box models have already been put to use. One designed to identify criminals likely to offend again turned out to be using racial cues rather than data about human psychology and behavior, she notes.
"Clinicians are right to be suspicious of these models, given all the other problems we've had with proprietary models," Rudin says.
"The right question to ask is, 'When is a black box OK?' " says Nigam Shah, who specializes in biomedical informatics at Stanford.
Shah developed an algorithm that could scan medical records for people who had just been admitted to the hospital, to identify those most likely to die soon. It wasn't very accurate, but it didn't need to be — it flagged some of the most severe cases and referred them to doctors to see whether they were candidates for palliative care. He likens it to a Google search, in which you care only about the top results being on target.
Shah sees no problem using a black box in this case — even an inaccurate one. It performed the task it was intended to.
While the algorithm worked technically, Stanford palliative care physician Stephanie Harman says it ended up being more confusing than helpful in selecting patients for her service, because people in most need of this service aren't necessarily those closest to death.
Shah says, if you're insisting on an algorithm that's explainable, you need to ask, explainable to whom? "Physicians use things that they don't understand how they work all the time," he says. "For the majority of the drugs, we have no idea how they work."
In his view, what really matters is whether an algorithm gets enough testing along the way to assure doctors and federal regulators that it is dependable and suitable for its intended use. And it is equally important to avoid misuse of an algorithm, for example if a health insurer tried to use Shah's death-forecasting algorithm to make decisions about whether to pay for medical care.
"I firmly believe that we should be thinking about algorithms differently," Shah says. "We need to worry more about the cost of the action that will be taken, who will take that action" and a host of related questions that determine its value in medical care. He says that matters a lot more than whether the algorithm is a black box.
You can contact NPR science correspondent Richard Harris at rharris@npr.org.
Links
- Carle Illinois College Of Medicine Seeks Community Input For Health Care Innovation
- Why Are There So Few Black Men In Medicine?
- Telemedicine Helps Reach Stroke Patients in Rural Illinois
- Medical Foods Are Vital For A Rare Disease. Why Doesn’t Insurance Cover Them?
- Preventive Dental Services For Adults Now Covered In Illinois’ Medicaid Program
- An Opioid Prescription In Illinois Could Be A Ticket For Medical Marijuana
